7.1 — Probability Measure ও Weak Law¶
এই অধ্যায়ে কী শিখব: probability space (নমুনা স্থান), random variable (দৈবচল), expectation (প্রত্যাশিত মান) ও variance (বিচ্ছুরণ), independent events (স্বাধীন ঘটনা) ও random variables, conditional probability (শর্তাধীন সম্ভাবনা) ও Bayes' theorem, distribution ও density function, এবং Weak Law of Large Numbers — measure theory-ই আধুনিক probability-র মূলভিত্তি।
উৎস (source): Kolmogorov (probability axioms); Bernoulli (weak law of large numbers)।
১. কেন শিখব? (Motivation)¶
তুমি এতদিন measure (পরিমাপ) শিখেছ — Lebesgue measure, signed measure, \(L^p\) space। এখন হঠাৎ probability? কারণটা চমকপ্রদ: probability-ই আসলে measure theory-র একটা বিশেষ ক্ষেত্র — শুধু একটা শর্ত আলাদা, পুরো space-এর measure ঠিক \(1\)।
এটা বুঝলে দুটো বিশাল উপকার হয়। প্রথমত, measure theory-র সব theorem — Dominated Convergence, Radon-Nikodym, \(L^2\) duality — এখন সরাসরি probability-তেও কাজ করে। দ্বিতীয়ত, probability-র ধারণাগুলো — sample space, event, expectation — এখন সঠিক mathematical ভিত্তিতে দাঁড়ায়।
ভাবো, class-এ গড়পড়তা নম্বর বের করতে হবে। তুমি \(n\) জনের নম্বর মেপে average নাও। \(n\) বাড়লে এই average কি আসল মানের কাছে যায়? এটা নিজেই একটা মাপার প্রশ্ন — আর Weak Law of Large Numbers (বৃহৎ সংখ্যার দুর্বল নিয়ম) দেয় এর নিখুঁত গণিত-উত্তর।
মূল স্বজ্ঞা
Probability মানে একটা সরলীকৃত measure theory — শুধু শর্ত হলো \(P(\Omega) = 1\)। "Probability = 40%" মানে \(P(A) = 0.4\), ঠিক measure \(0.4\) এর মতো। কিন্তু এই নির্দিষ্ট শর্তের কারণে "independence" এবং "weak law" এর মতো ধারণা উদ্ভব হয় যা সাধারণ measure theory-তে থাকে না।
২. মূল ধারণা (Core idea)¶
Probability Space — সম্ভাবনার মহাবিশ্ব¶
Probability theory-র পুরো মঞ্চ হলো তিনটে বস্তুর সমষ্টি: \((\Omega, \mathcal{F}, P)\)।
- \(\Omega\) (omega, sample space / নমুনা স্থান) — সমস্ত সম্ভাব্য ফলাফলের সেট। একটা পাশা ছুঁড়লে \(\Omega = \{1,2,3,4,5,6\}\)।
- \(\mathcal{F}\) — \(\Omega\)-এর উপর একটা \(\sigma\)-algebra (sigma-algebra); এর প্রতিটা সদস্যকে বলে event (ঘটনা)।
- \(P\) — একটা measure on \((\Omega, \mathcal{F})\) যেখানে \(P(\Omega) = 1\)।
এই \(P\)-ই হলো probability measure (সম্ভাবনা পরিমাপ)। আগের অধ্যায়ে আমরা Lebesgue measure \(\lambda\), signed measure \(\nu\) দেখেছিলাম — \(P\) ঠিক তাদেরই এক বিশেষ রূপ, শুধু সে জানে যে সব-মিলিয়ে ঠিক \(1\)।
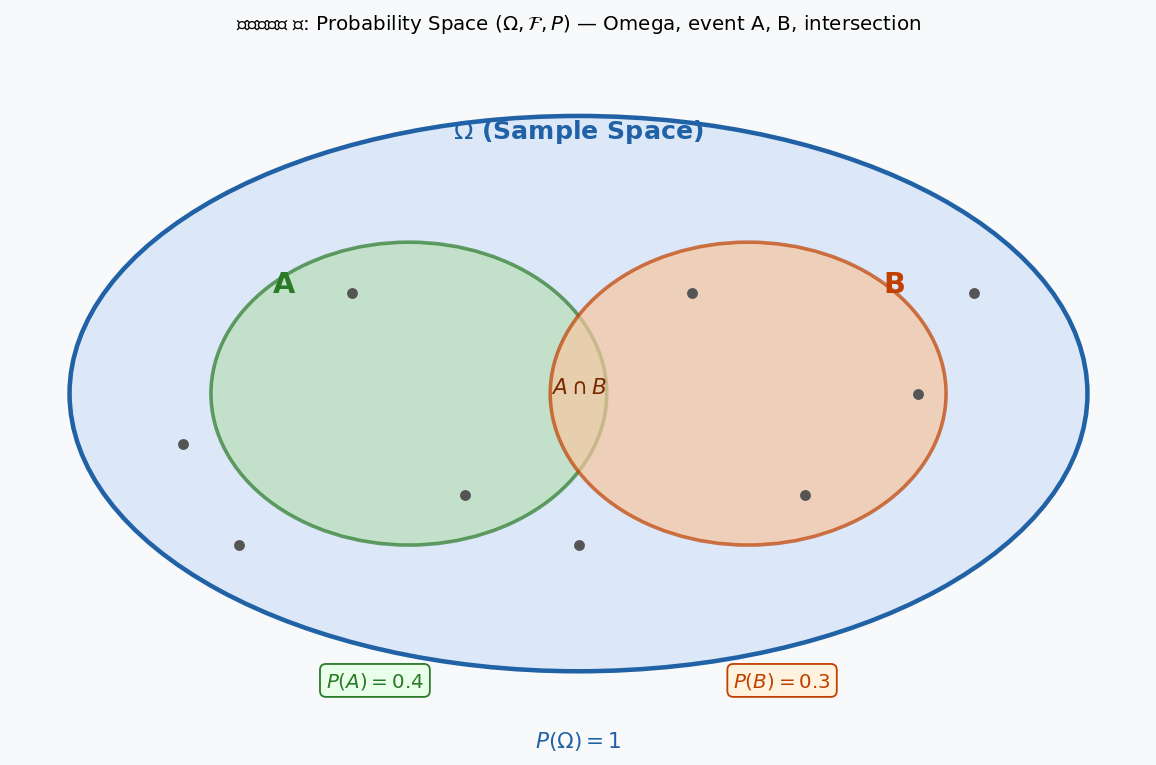
চিত্র ১: Probability space \((\Omega, \mathcal{F}, P)\)। পুরো উপবৃত্ত হলো \(\Omega\); সবুজ \(A\) ও কমলা \(B\) হলো দুটো event; \(P(\Omega) = 1\), \(P(A) = 0.4\), \(P(B) = 0.3\)।
Random Variable — ফলাফলকে সংখ্যায় রূপান্তর¶
একটা random variable (দৈবচল) \(X\) হলো একটা measurable function \(X: \Omega \to \mathbb{R}\)। প্রতিটা sample outcome \(\omega\) কে সে একটা সংখ্যায় রূপান্তরিত করে।
উদাহরণ: পাশা ছুঁড়লে \(\Omega = \{1,...,6\}\), আর \(X(\omega) = \omega\) হলে \(X\) পাশার মুখ দেখায়। কিন্তু \(Y(\omega) = \omega^2\) নিলে \(Y\) পাশার মুখের বর্গ দেয়।
এই measurability শর্তটা জরুরি: \(\{X \leq s\} = \{\omega : X(\omega) \leq s\} \in \mathcal{F}\) — অর্থাৎ "X কত এর চেয়ে ছোট" প্রশ্নটা \(P\) দিয়ে মাপা যাবে।
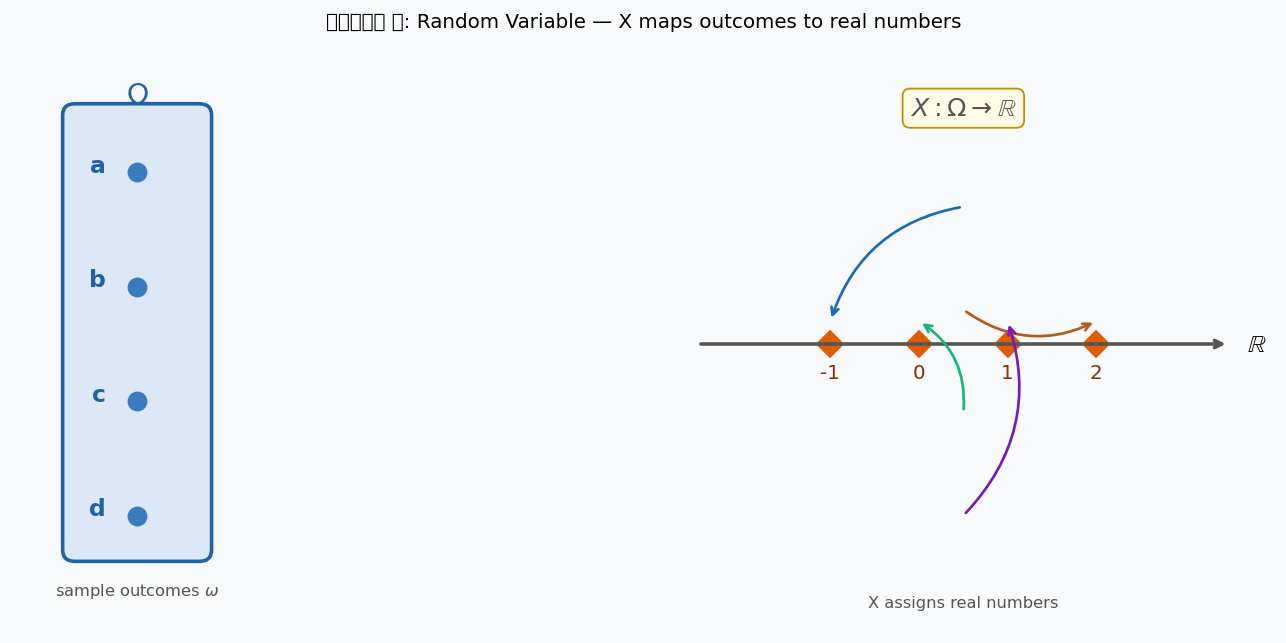
চিত্র ২: Random variable \(X: \Omega \to \mathbb{R}\) — প্রতিটা outcome \(\omega\) (বাঁয়ে) কে একটা সংখ্যায় (ডানে) নিয়ে যায়। তীরচিহ্নগুলো বিভিন্ন mapping দেখাচ্ছে।
৩. সংজ্ঞা ও উপপাদ্য (Definitions & Theorems)¶
Probability Space ও Event¶
সংজ্ঞা ১২.১ (Axler): Probability Measure
\(\mathcal{F}\) যদি \(\Omega\)-এর উপর একটা \(\sigma\)-algebra হয়, তাহলে \(P: \mathcal{F} \to [0,1]\) কে probability measure (সম্ভাবনা পরিমাপ) বলা হয় যদি:
- \(P(\Omega) = 1\)
- \(P\) countably additive: \(E_1, E_2, \ldots\) disjoint হলে \(P\!\bigl(\bigcup_{n=1}^\infty E_n\bigr) = \sum_{n=1}^\infty P(E_n)\)
Triple \((\Omega, \mathcal{F}, P)\) কে বলে probability space (সম্ভাবনা স্থান)।
notation পার্থক্য: measure theory-তে আমরা লিখতাম \((X, \mathcal{S}, \mu)\); probability theory-তে convention হলো \((\Omega, \mathcal{F}, P)\) — \(\Omega\) মানে পুরো নমুনা জগত, \(\mathcal{F}\) মানে "filtration" (events-এর পরিবার), \(P\) মানে probability। নতুন নাম, পুরনো ধারণা।
Expectation ও Variance¶
সংজ্ঞা ১২.১৩ (Axler): Random Variable ও Expectation
\((\Omega, \mathcal{F}, P)\) probability space হলে:
- \(X: \Omega \to \mathbb{R}\) measurable হলে \(X\) কে বলে random variable (দৈবচল)।
- \(X \in L^1(P)\) হলে \(X\)-এর expectation (প্রত্যাশিত মান) হলো:
\(EX\) আসলে \(X\)-এর "গড় মান" — সব outcome-এর \(X\)-মানকে তাদের probability দিয়ে ভারযুক্ত করে যোগ করা।
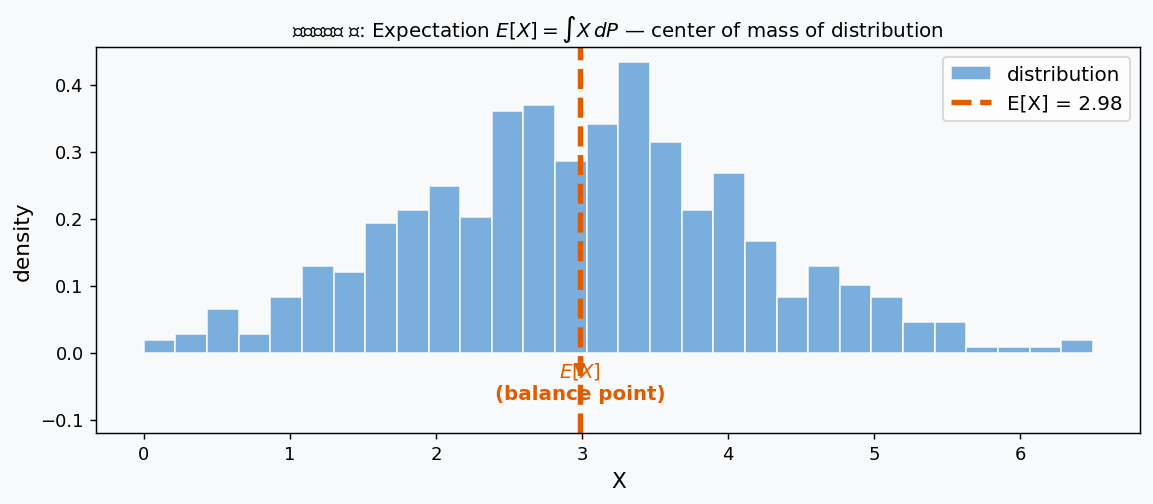
চিত্র ৩: Expectation \(E[X]\) হলো distribution-এর center of mass (ভরকেন্দ্র) — কমলা ড্যাশলাইন দেখাচ্ছে সেই balance point।
সংজ্ঞা ১২.১৮ (Axler): Variance ও Standard Deviation
\(X \in L^2(P)\) হলে:
- Variance (বিচ্ছুরণ): \(\sigma^2(X) = E\bigl[(X - EX)^2\bigr]\)
- Standard Deviation (প্রমাণ বিচ্যুতি): \(\sigma(X) = \sqrt{\sigma^2(X)}\)
Shortcut formula (সংক্ষিপ্ত সূত্র):
স্বজ্ঞা: variance বলছে \(X\) কতটা "ছড়িয়ে" আছে তার মানের চারপাশে। ছোট variance = tight distribution; বড় variance = spread-out distribution।
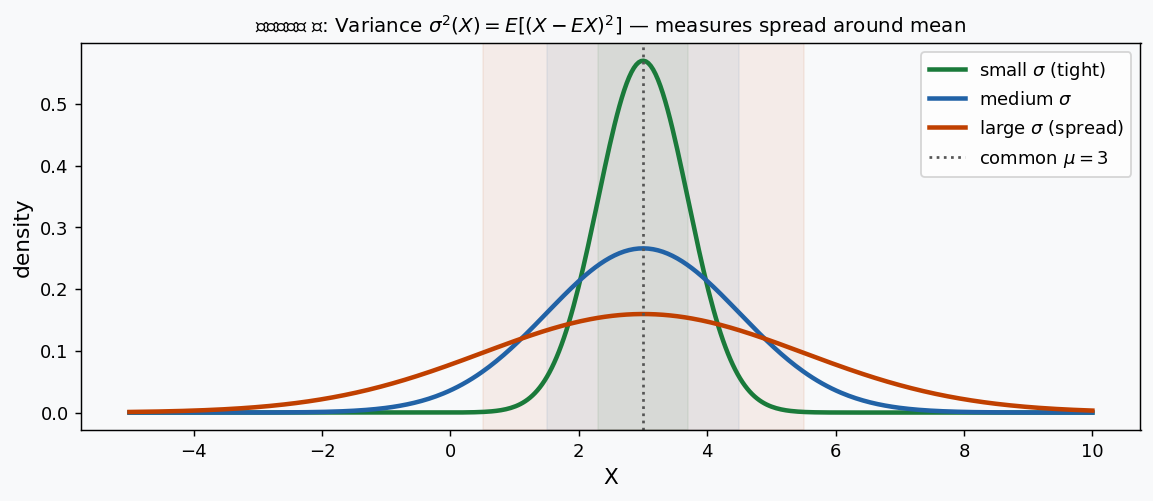
চিত্র ৪: তিনটে normal distribution একই mean \(\mu = 3\) কিন্তু আলাদা \(\sigma\) নিয়ে। সবুজ (ছোট \(\sigma\)) = tight; লাল (বড় \(\sigma\)) = spread।
Independent Events ও Random Variables¶
এটাই probability-র সবচেয়ে বিশেষ ধারণা — measure theory-তে এই ধারণা নেই।
সংজ্ঞা ১২.৭ (Axler): Independent Events
\(A, B \in \mathcal{F}\) দুটো independent (স্বাধীন) ঘটনা যদি:
সাধারণভাবে \(\{A_k\}_{k \in \Gamma}\) পরিবার independent যদি প্রতিটা finite subcollection \(k_1, \ldots, k_n\) এর জন্য:
স্বজ্ঞা: \(A\) ও \(B\) independent মানে \(B\) ঘটে কিনা জানলে \(A\) সম্পর্কে নতুন কিছু শেখার নেই। একটা fair coin-এর ৩য় ও ৪র্থ toss সম্পূর্ণ independent।
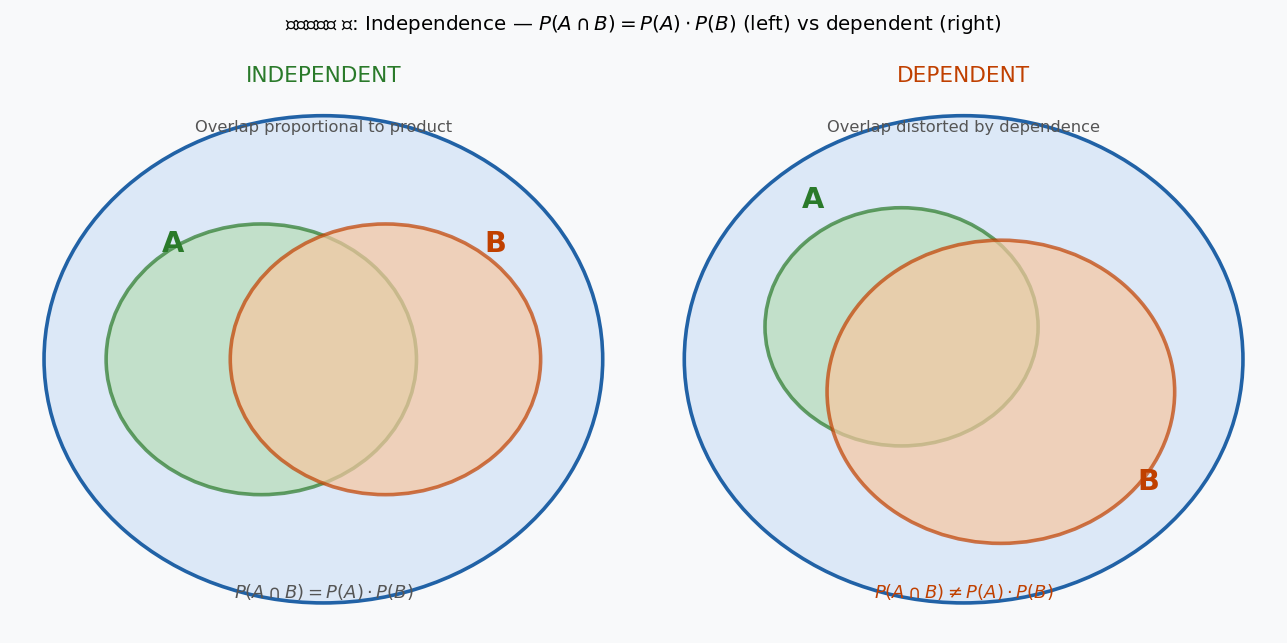
চিত্র ৫: বাঁয়ে independent ঘটনা — \(A \cap B\)-এর area ঠিক \(P(A) \cdot P(B)\)-এর সমান। ডানে dependent ঘটনা — overlap বেশি বা কম।
সংজ্ঞা ১২.১৪ (Axler): Independent Random Variables
\(X, Y\) দুটো random variable independent (স্বাধীন) যদি সব Borel sets \(U, V \subseteq \mathbb{R}\) এর জন্য:
মূল ফলাফল (১২.১৭): \(X, Y \in L^2(P)\) independent হলে \(E(XY) = EX \cdot EY\)।
Variance-এর সমষ্টি (১২.২২): \(X_1, \ldots, X_n \in L^2(P)\) independent হলে:
এটা variance-এর জন্য Pythagoras theorem-এর মতো — independent হলে variance সরাসরি যোগ হয়।
Conditional Probability ও Bayes' Theorem¶
সংজ্ঞা ১২.২৩ (Axler): Conditional Probability
\(B \in \mathcal{F}\) এবং \(P(B) > 0\) হলে \(A\)-এর \(B\)-শর্তে conditional probability (শর্তাধীন সম্ভাবনা) হলো:
স্বজ্ঞা: "\(B\) জানা গেছে" — এই আলোকে \(A\)-এর সম্ভাবনা কত? \(P_B\) নিজেই \((\Omega, \mathcal{F})\)-তে একটা probability measure।
উপপাদ্য ১২.২৪–১২.২৫ (Axler): Bayes' Theorem
(প্রথম রূপ): \(P(A), P(B) > 0\) হলে:
(দ্বিতীয় রূপ): \(A_1, \ldots, A_n\) pairwise disjoint, \(A_1 \cup \cdots \cup A_n = \Omega\), সবার \(P > 0\):
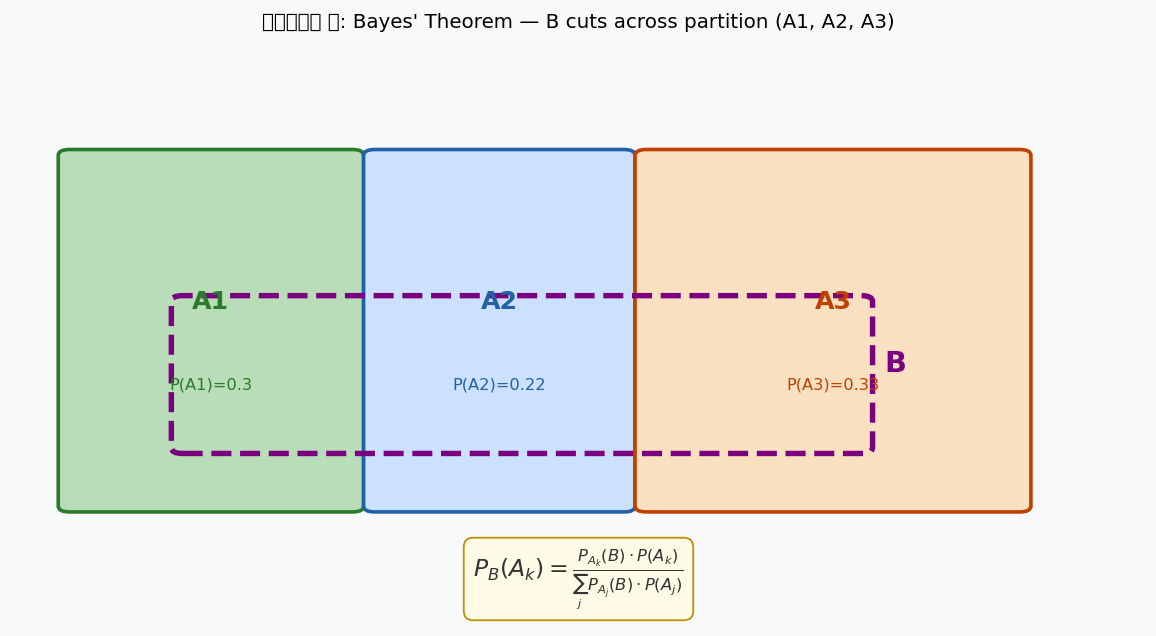
চিত্র ৬: Bayes' Theorem — \(B\) (বেগুনি ড্যাশ) তিনটা partition \(A_1, A_2, A_3\) কেটে যায়। \(P_B(A_k)\) বের করতে আমরা "পিছনে গিয়ে" হিসেব করি।
স্বজ্ঞা: Bayes' theorem হলো "পিছনে তাকানো" — "\(B\) ঘটেছে দেখে \(A_k\)-এর কোনটা সত্য হওয়ার সম্ভাবনা কত?" এটা machine learning-এর Bayesian inference-এর ভিত্তি।
Distribution Function ও Density Function¶
সংজ্ঞা ১২.২৭ (Axler): Distribution ও CDF
\(X\) random variable হলে:
- Probability distribution (সম্ভাবনা বিতরণ): \(P_X: \mathcal{B} \to [0,1]\) defined by \(P_X(B) = P(X \in B)\)
- Distribution function / CDF (বিতরণ ফাংশন): \(\widetilde{X}: \mathbb{R} \to [0,1]\) defined by \(\widetilde{X}(s) = P(X \leq s)\)
সংজ্ঞা ১২.৩২ (Axler): Density Function
যদি কোনো \(h \in L^1(\mathbb{R})\) পাওয়া যায় যেন:
তাহলে \(h\) কে \(X\)-এর density function (ঘনত্ব ফাংশন) বলে। এবং:
গুরুত্বপূর্ণ উদাহরণ:
| Distribution | \(h(x)\) | \(EX\) | \(\sigma(X)\) |
|---|---|---|---|
| Uniform \([0,1]\) | \(\mathbf{1}_{[0,1]}\) | \(\frac{1}{2}\) | \(\frac{1}{2\sqrt3}\) |
| Exponential \(\alpha\) | \(\alpha e^{-\alpha x}\) (\(x \geq 0\)) | \(\frac{1}{\alpha}\) | \(\frac{1}{\alpha}\) |
| Standard Normal | \(\frac{1}{\sqrt{2\pi}} e^{-x^2/2}\) | \(0\) | \(1\) |
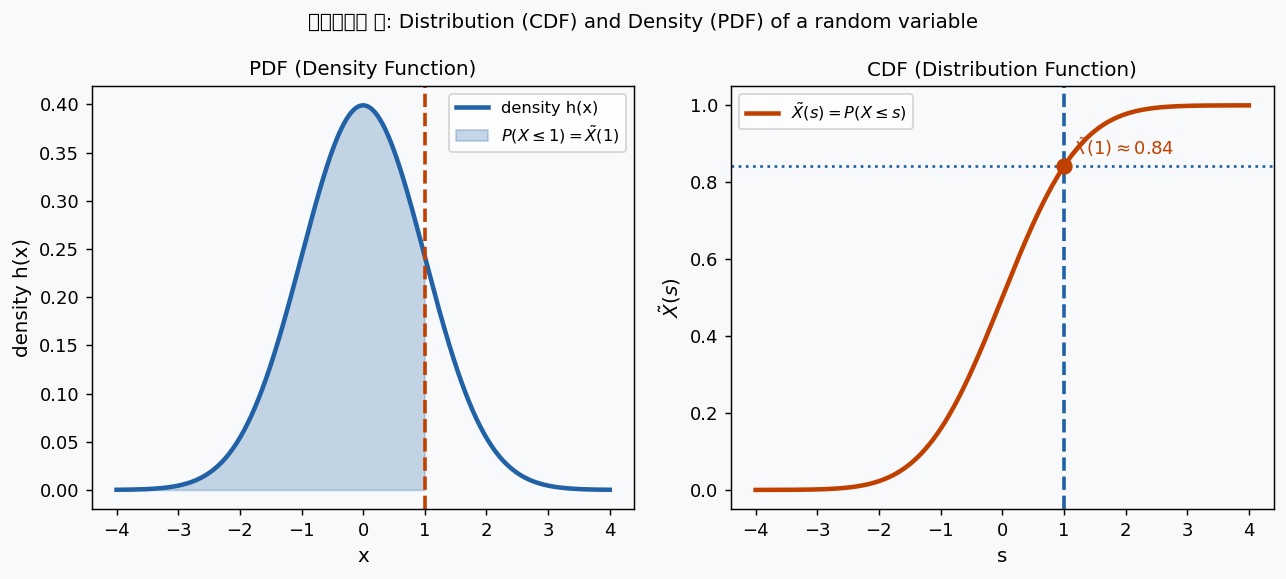
চিত্র ৭: বাঁয়ে density (PDF) \(h(x)\) — নীল ছায়া হলো \(P(X \leq 1)\)। ডানে distribution function (CDF) \(\widetilde{X}(s) = P(X \leq s)\) — একটা non-decreasing function যা \(0\) থেকে \(1\)-এ যায়।
Weak Law of Large Numbers¶
সংজ্ঞা ১২.৩৫ (Axler): i.i.d. Family
Random variables \(\{X_k\}\) কে i.i.d. (independent identically distributed) বলা হয় যদি তারা: - independent: সব \(k\) এর জন্য \(\{X_k\}\) independent - identically distributed: সব \(j, k\) এর জন্য \(P(X_j \leq s) = P(X_k \leq s)\) সব \(s\)-এর জন্য
উপপাদ্য ১২.৩৮ (Axler): Weak Law of Large Numbers (বৃহৎ সংখ্যার দুর্বল নিয়ম)
\(\{X_k\}_{k \in \mathbb{Z}^+}\) i.i.d. এবং \(X_k \in L^2(P)\), \(EX_k = \mu\) হলে, যেকোনো \(\varepsilon > 0\) এর জন্য:
প্রমাণের মূল ধারণা:
প্রথমে দেখাই \(E\!\left[\frac{1}{n}\sum X_k\right] = \mu\) এবং \(\sigma^2\!\left[\frac{1}{n}\sum X_k\right] = \frac{\sigma^2}{n}\)।
তারপর Chebyshev's inequality (১২.২১) প্রয়োগ করি: \(P\!\left(\lvert Y - EY\rvert \geq t\sigma(Y)\right) \leq \frac{1}{t^2}\)।
\(Y = \frac{1}{n}\sum X_k\), \(t = \frac{\varepsilon\sqrt{n}}{\sigma}\) নিলে:
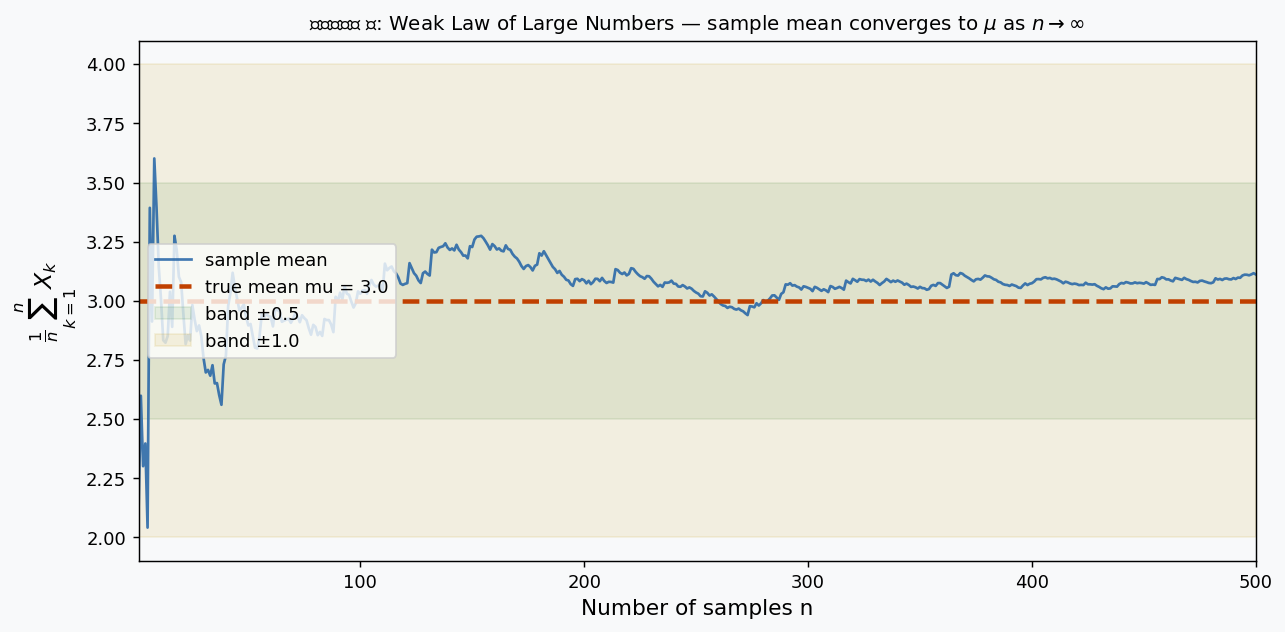
চিত্র ৮: Weak Law of Large Numbers। নীল রেখা sample mean \(\frac{1}{n}\sum X_k\); লাল ড্যাশ true mean \(\mu = 3\); সবুজ/হলুদ ব্যান্ড \(\pm\varepsilon\)। \(n\) বাড়লে sample mean ব্যান্ডের ভেতরে থাকে।
৪. উদাহরণ ও Analogy¶
উদাহরণ ১: Coin Toss — পাশার খেলা¶
\(\Omega = \{H, T\}^4\) (চারটা coin toss)। \(P = \frac{\text{counting measure}}{16}\)।
\(A = \{\omega : \omega_1 = \omega_2 = \omega_3 = H\}\), \(B = \{\omega : \omega_4 = H\}\)।
তাহলে \(P(A) = \frac{2}{16} = \frac{1}{8}\), \(P(B) = \frac{8}{16} = \frac{1}{2}\)।
\(P(A \cap B) = \frac{1}{16} = \frac{1}{8} \cdot \frac{1}{2} = P(A) \cdot P(B)\) — সুতরাং \(A\) ও \(B\) independent। কারণ: ৪র্থ toss-এর ফলাফল প্রথম তিনটার উপর নির্ভর করে না।
উদাহরণ ২: Normal Distribution-এর mean ও variance¶
\(h(x) = \frac{1}{\sqrt{2\pi}} e^{-x^2/2}\) নিলে \(P(B) = \int_B h\, d\lambda\)। এই \(P\) হলো standard normal-এর probability measure।
Analogy: গড় পরীক্ষার নম্বর¶
ধরো একটা class-এ প্রতিটা student-এর নম্বর একটা i.i.d. random variable। তাহলে Weak Law বলছে: যত বেশি student-এর নম্বর নেবে, class-এর গড় নম্বর ততই আসল "প্রত্যাশিত নম্বর"-এর কাছে যাবে। \(50\) জনের গড় \(10\) জনের গড়ের চেয়ে বেশি reliable।
৫. সাধারণ ভুল (Common mistakes)¶
-
"\(P(A) = 0\) মানে \(A\) অসম্ভব" ভাবা। Lebesgue measure-এ যেমন \(\lambda(\{x\}) = 0\) হলেও \(x\) exist করে, তেমনি \(P(A) = 0\) হলেও \(A\) ঘটতে পারে। "Almost surely" শব্দটা ঠিক এজন্যই আলাদা।
-
Independence ও disjoint গুলিয়ে ফেলা। \(A \cap B = \emptyset\) (disjoint) হলে \(P(A \cap B) = 0 \neq P(A)P(B)\) সাধারণত — তাই disjoint events সাধারণত dependent, independent নয়!
-
Expectation of product = product of expectations। এটা শুধু independent random variables-এর জন্য সত্য। সাধারণত \(E(XY) \neq EX \cdot EY\)।
-
Weak Law = Strong Law ভাবা। Weak Law বলে probability converges to \(0\); Strong Law (এই বইয়ে নেই) বলে almost surely converges। এরা আলাদা।
-
Density function সবসময় থাকে না। \(P = \delta_0\) (point mass at \(0\)) এর কোনো Lebesgue density নেই। Density থাকতে হলে \(P_X \ll \lambda\) (absolutely continuous) হওয়া জরুরি।
-
\(\widetilde{X}\) right-continuous হওয়াটা ভুলে যাওয়া। CDF সবসময় right-continuous — \(\lim_{t \downarrow s} \widetilde{X}(t) = \widetilde{X}(s)\)।
৬. এক্সারসাইজ (Exercises)¶
নিজে চেষ্টা করো, তারপর নিচের সমাধান খোলো।
-
\(\Omega = \{1,2,...,6\}\) (পাশা), \(P =\) counting measure / 6। \(A = \{2,4,6\}\) (জোড়), \(B = \{1,2,3\}\) (প্রথম তিন)। \(P_B(A)\) বের করো এবং \(A,B\) independent কিনা পরীক্ষা করো।
-
\(X\) uniform on \([0,1]\) (density \(h = \mathbf{1}_{[0,1]}\))। \(EX\), \(EX^2\), এবং \(\sigma^2(X)\) বের করো।
-
\(X, Y\) independent, \(EX = 3\), \(EY = 2\), \(\sigma^2(X) = 4\), \(\sigma^2(Y) = 1\)। \(E(X+Y)\), \(E(XY)\), \(\sigma^2(X+Y)\) বের করো।
-
Chebyshev's inequality প্রয়োগ করো: \(X \in L^2(P)\), \(EX = 5\), \(\sigma(X) = 2\)। \(P(\lvert X - 5\rvert \geq 4)\) এর upper bound বের করো।
-
\(\{X_k\}\) i.i.d. uniform on \([0,1]\)। Weak Law-এ \(\mu = EX_k\) কত? \(n = 100\) এর জন্য \(P\!\bigl(\lvert\bar{X}_{100} - \mu\rvert \geq 0.1\bigr)\) এর upper bound বের করো।
-
\(h_\alpha(x) = \alpha e^{-\alpha x}\) (\(x \geq 0\), \(\alpha > 0\), exponential density)। দেখাও যে \(\int_0^\infty h_\alpha\, d\lambda = 1\), এবং \(EX = 1/\alpha\), \(\sigma(X) = 1/\alpha\) verify করো।
-
\(A_1 = \{\omega\colon \omega_1 = H\}\), \(A_2 = \{\omega\colon \omega_2 = H\}\), \(A_3 = \{\omega\colon \omega_1 = \omega_2\}\) তিনটা event on \(\{H,T\}^2\), \(P =\) counting / 4। দেখাও যে কোনো দুটো pairwise independent কিন্তু তিনটা একসাথে independent নয়।
-
Borel-Cantelli Lemma verify: \((\Omega, \mathcal{F}, P) = ([0,1], \mathcal{B}, \lambda)\), \(A_n = [0, \frac{1}{n}]\)। \(\sum P(A_n) = \infty\) কিন্তু \(\lambda(\limsup A_n) = ?\) (strong vs weak law connection)।
৭. সমাধান (ব্যাখ্যাসহ)¶
১-নং সমাধান দেখাও
\(P(A) = \frac{3}{6} = \frac{1}{2}\), \(P(B) = \frac{3}{6} = \frac{1}{2}\)।
\(A \cap B = \{2\}\), তাই \(P(A \cap B) = \frac{1}{6}\)।
\(P_B(A) = \frac{P(A \cap B)}{P(B)} = \frac{1/6}{1/2} = \frac{1}{3}\)।
Independence check: \(P(A) \cdot P(B) = \frac{1}{2} \cdot \frac{1}{2} = \frac{1}{4} \neq \frac{1}{6} = P(A \cap B)\)।
সিদ্ধান্ত: \(A\) ও \(B\) dependent — \(B\) জানলে \(A\)-এর সম্ভাবনা \(\frac{1}{2}\) থেকে \(\frac{1}{3}\)-এ নামে।
২-নং সমাধান দেখাও
\(X \sim \text{Uniform}[0,1]\), \(h(x) = \mathbf{1}_{[0,1]}\)।
সুতরাং \(\sigma(X) = \frac{1}{2\sqrt{3}}\)। এটা Axler 12.34-এর সাথে মিলছে।
৩-নং সমাধান দেখাও
\(E(X+Y) = EX + EY = 3 + 2 = 5\)।
\(E(XY) = EX \cdot EY = 3 \cdot 2 = 6\) (independence থেকে, Axler 12.17)।
\(\sigma^2(X+Y) = \sigma^2(X) + \sigma^2(Y) = 4 + 1 = 5\) (independence থেকে, Axler 12.22)।
মনে রাখো: variance additive হওয়ার জন্য independence জরুরি। \(\sigma(X+Y) = \sqrt{5}\)।
৪-নং সমাধান দেখাও
Chebyshev (Axler 12.21): \(P(\lvert X - EX\rvert \geq t\sigma(X)) \leq \frac{1}{t^2}\)।
এখানে \(\lvert X - 5\rvert \geq 4 = 2\sigma(X)\), তাই \(t = 2\)।
এই bound টা tight নয় কিন্তু distribution না জেনেই পাওয়া যায় — এটাই Chebyshev-এর শক্তি।
৫-নং সমাধান দেখাও
\(X_k \sim \text{Uniform}[0,1]\), তাই \(\mu = EX_k = \frac{1}{2}\), \(\sigma^2(X_k) = \frac{1}{12}\)।
Weak Law proof-এর bound থেকে:
তাই \(P \leq \frac{1}{12} \approx 0.083\)। \(n = 100\) নেওয়াতে এই সম্ভাবনা \(\leq 8.3\%\)।
৬-নং সমাধান দেখাও
\(\int_0^\infty \alpha e^{-\alpha x}\, dx = \alpha \cdot \left[-\frac{1}{\alpha} e^{-\alpha x}\right]_0^\infty = \alpha \cdot \frac{1}{\alpha} = 1\) ✓
Integration by parts: \(u = x\), \(dv = \alpha e^{-\alpha x}\, dx\) দিলে \(EX = \frac{1}{\alpha}\) ✓
\(\sigma^2(X) = EX^2 - (EX)^2 = \frac{2}{\alpha^2} - \frac{1}{\alpha^2} = \frac{1}{\alpha^2}\), তাই \(\sigma(X) = \frac{1}{\alpha}\) ✓
৭-নং সমাধান দেখাও
\(\Omega = \{HH, HT, TH, TT\}\), \(P = 1/4\) প্রতিটায়।
\(A_1 = \{HH, HT\}\), \(P(A_1) = 1/2\)। \(A_2 = \{HH, TH\}\), \(P(A_2) = 1/2\)। \(A_3 = \{HH, TT\}\), \(P(A_3) = 1/2\)।
Pairwise: \(A_1 \cap A_2 = \{HH\}\), \(P = 1/4 = P(A_1)P(A_2)\) ✓। একইভাবে বাকি দুই জোড়াও ✓।
কিন্তু \(A_1 \cap A_2 \cap A_3 = \{HH\}\), \(P = 1/4\)। \(P(A_1)P(A_2)P(A_3) = \frac{1}{2} \cdot \frac{1}{2} \cdot \frac{1}{2} = \frac{1}{8} \neq \frac{1}{4}\)।
সিদ্ধান্ত: Pairwise independent কিন্তু mutually independent নয় — এটা একটা বিখ্যাত উদাহরণ।
৮-নং সমাধান দেখাও
\(A_n = [0, 1/n]\), \(\lambda(A_n) = 1/n\)।
\(\sum_{n=1}^\infty P(A_n) = \sum \frac{1}{n} = \infty\) (harmonic series diverges)।
\(\limsup A_n = \bigcap_{m=1}^\infty \bigcup_{n=m}^\infty A_n\)।
যেকোনো \(\omega \in (0,1]\)-এর জন্য: \(\omega \in A_n = [0,1/n]\) যদি \(n \geq 1/\omega\), অর্থাৎ \(\omega \in A_n\) infinitely often। সুতরাং \(\limsup A_n = [0,1]\) এবং \(\lambda(\limsup A_n) = 1\)।
এটা Borel-Cantelli Lemma (12.6)-এর বিপরীত case — \(\sum P(A_n) = \infty\) হলে (কিন্তু independent নয়) \(P(\limsup A_n) = 1\) নাও হতে পারে। Independent case-এ (Axler 12.10) হতো।
৮. সারসংক্ষেপ ও Checklist¶
এই অধ্যায়ের পর নিজেকে যাচাই করো:
- [ ] Probability space \((\Omega, \mathcal{F}, P)\) বুঝি — শুধু একটা measure যেখানে \(P(\Omega) = 1\); measure theory-র সব theorem এখানে প্রযোজ্য।
- [ ] Random variable হলো measurable function \(\Omega \to \mathbb{R}\); expectation \(EX = \int X\, dP\) হলো integral।
- [ ] Variance \(\sigma^2(X) = E(X-EX)^2 = EX^2 - (EX)^2\) — spread পরিমাপ।
- [ ] Independence: \(P(A \cap B) = P(A)P(B)\); independent হলে \(E(XY) = EX \cdot EY\) এবং variance additive।
- [ ] Conditional probability \(P_B(A) = P(A \cap B)/P(B)\); Bayes' theorem দুটো রূপে লিখতে পারি।
- [ ] Distribution function (CDF) \(\widetilde{X}(s) = P(X \leq s)\) right-continuous, increasing, \(0 \to 1\)।
- [ ] Density function থাকলে \(\widetilde{X}(s) = \int_{-\infty}^s h\, d\lambda\); mean ও variance density দিয়ে বের করি।
- [ ] Weak Law of Large Numbers: i.i.d. family-র sample mean, Chebyshev দিয়ে, true mean-এ converge করে।
➡️ পরের অধ্যায়: 7.2 — The Daniell Integral — Lebesgue-এর পথ ছিল "আগে measure, তারপর integral"। Daniell-এর পথ উল্টো — আগে একটা functional (integral), পরে measure। দুটো পথেই একই গন্তব্য।